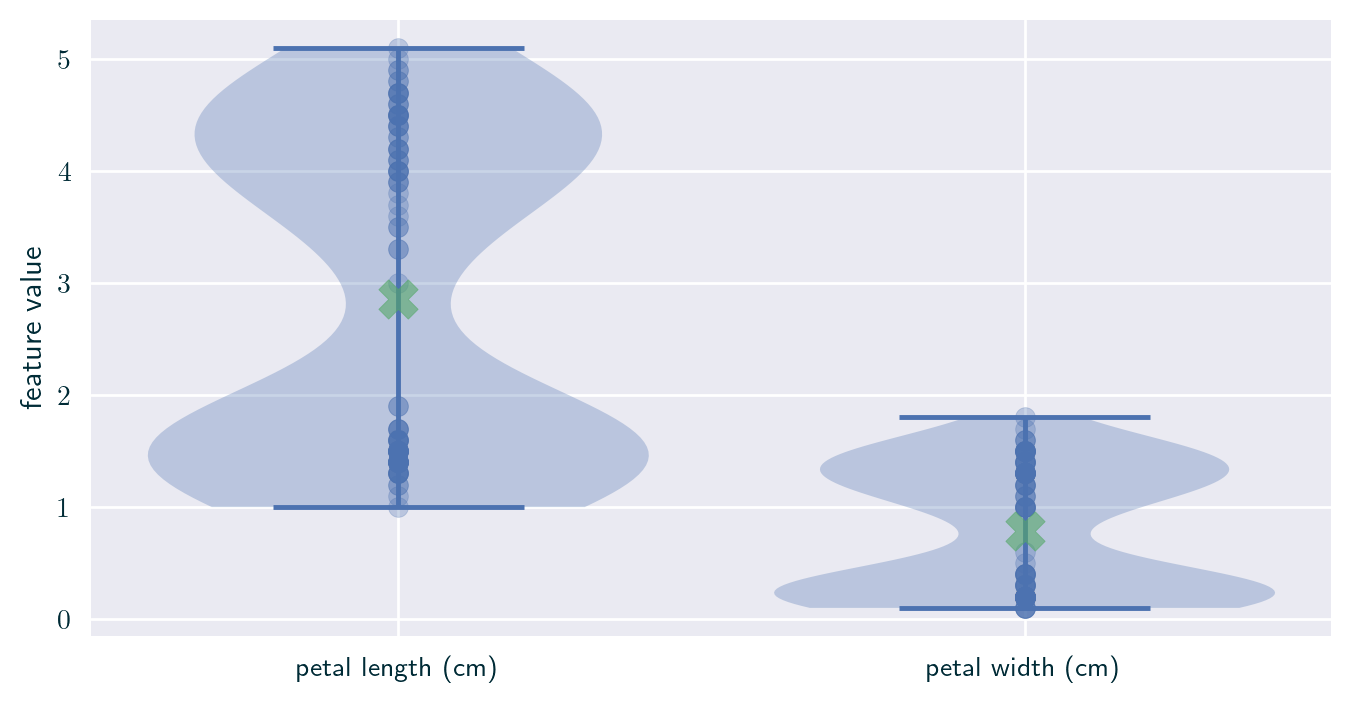
Linear Models
Toy Example
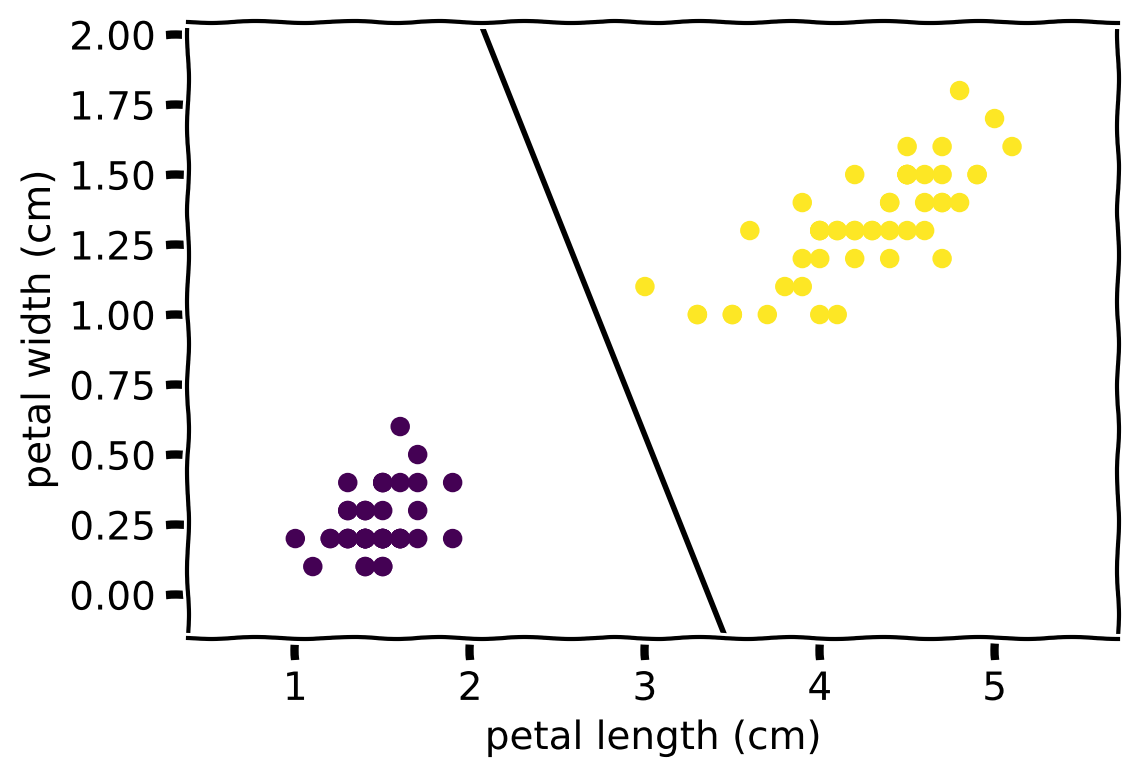
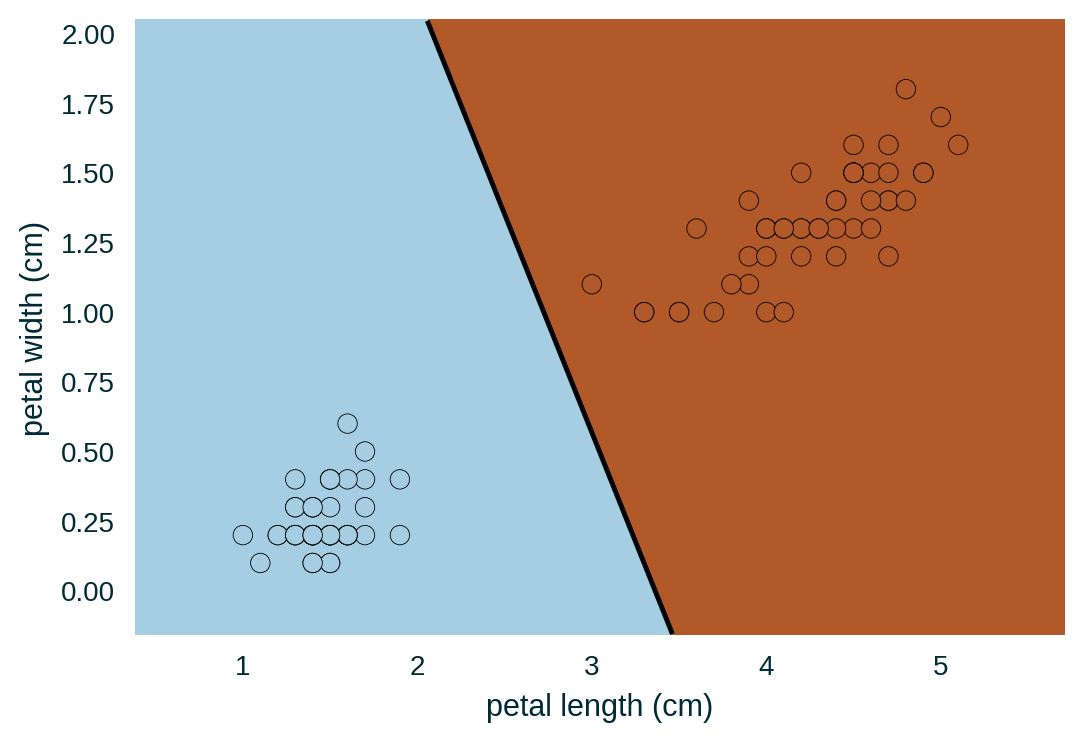
Model Visualisation
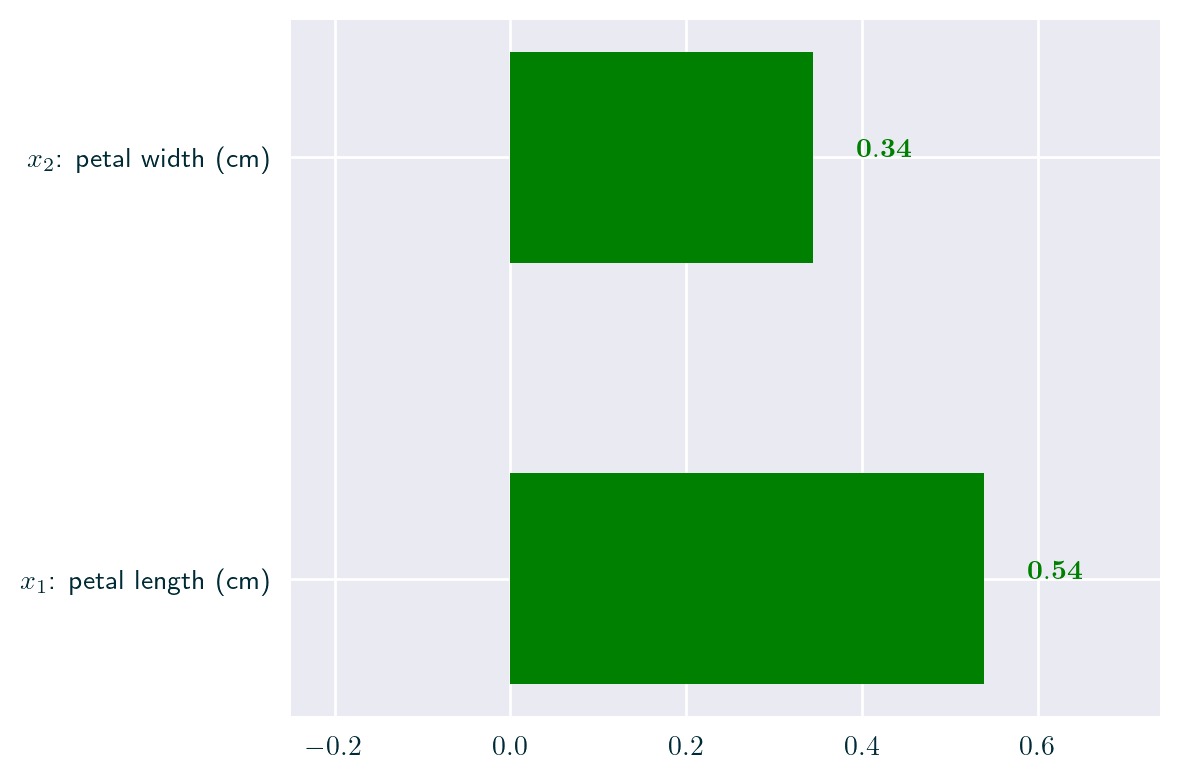
Feature Influence & Importance
Feature Effect
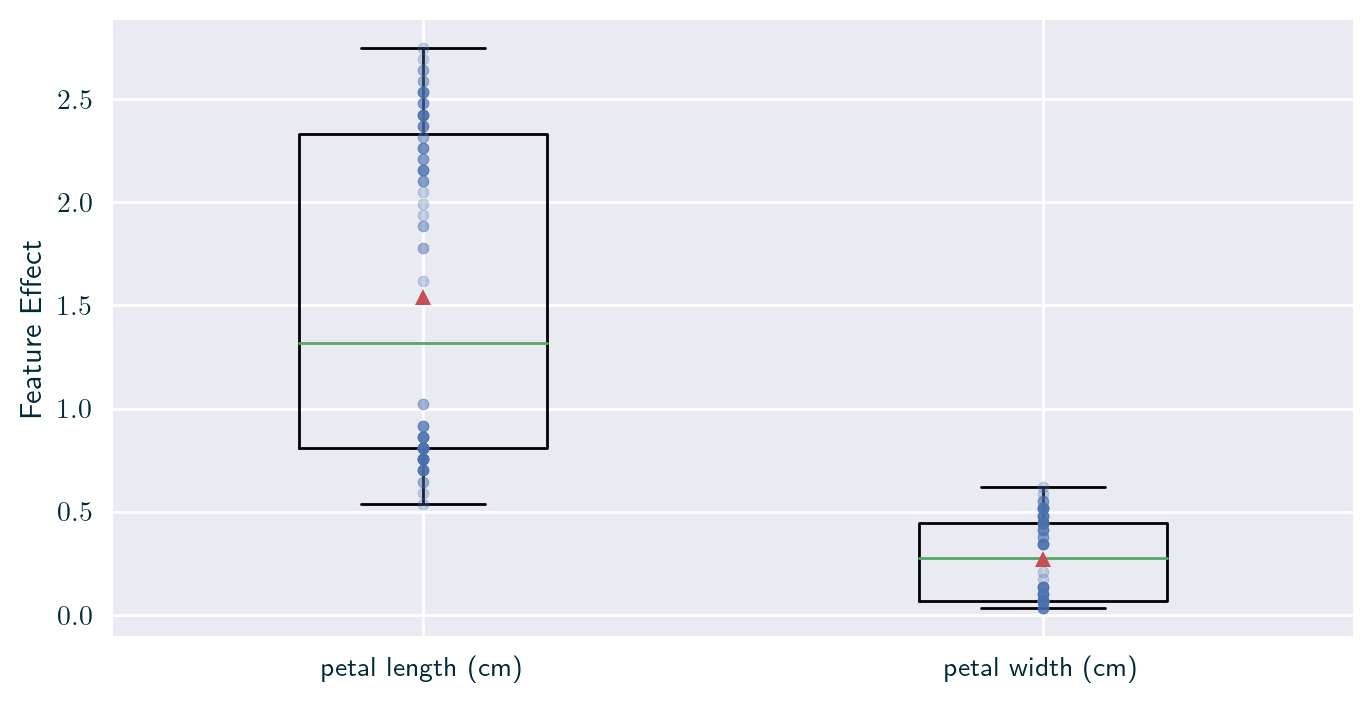
Feature Effect
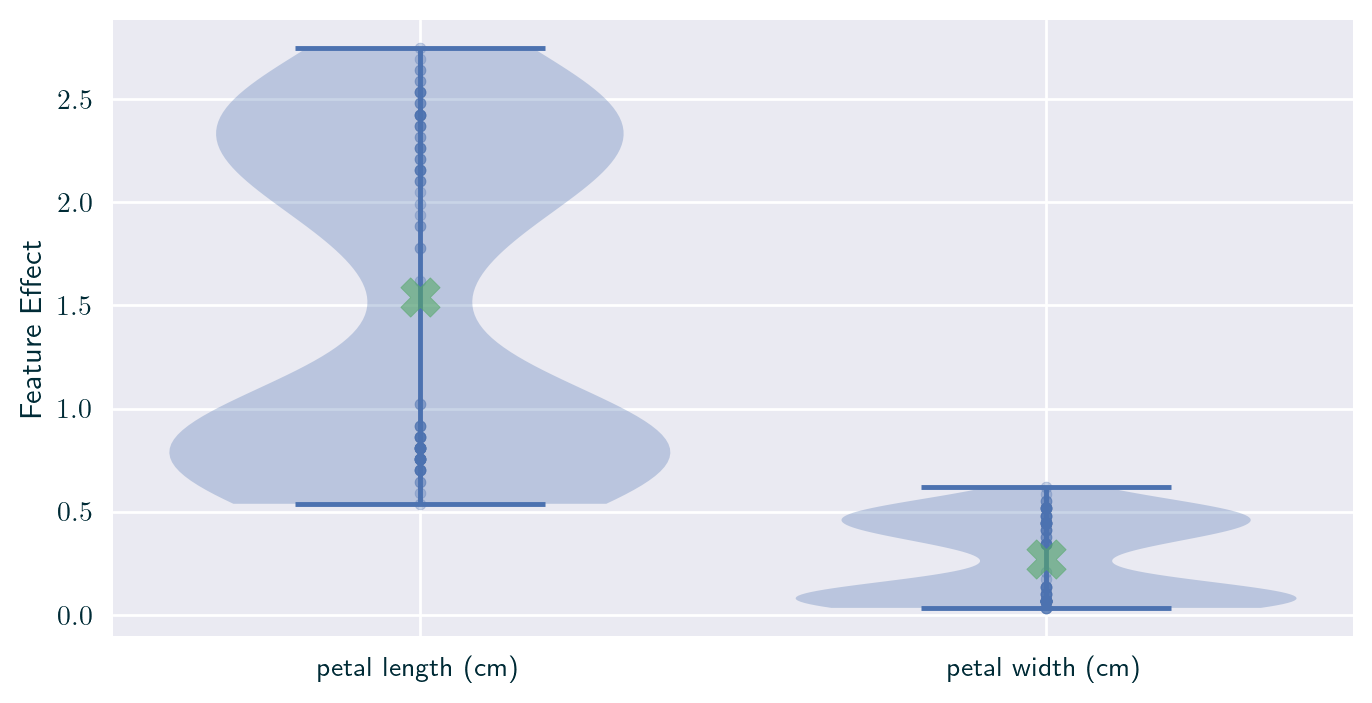
Individual Effect
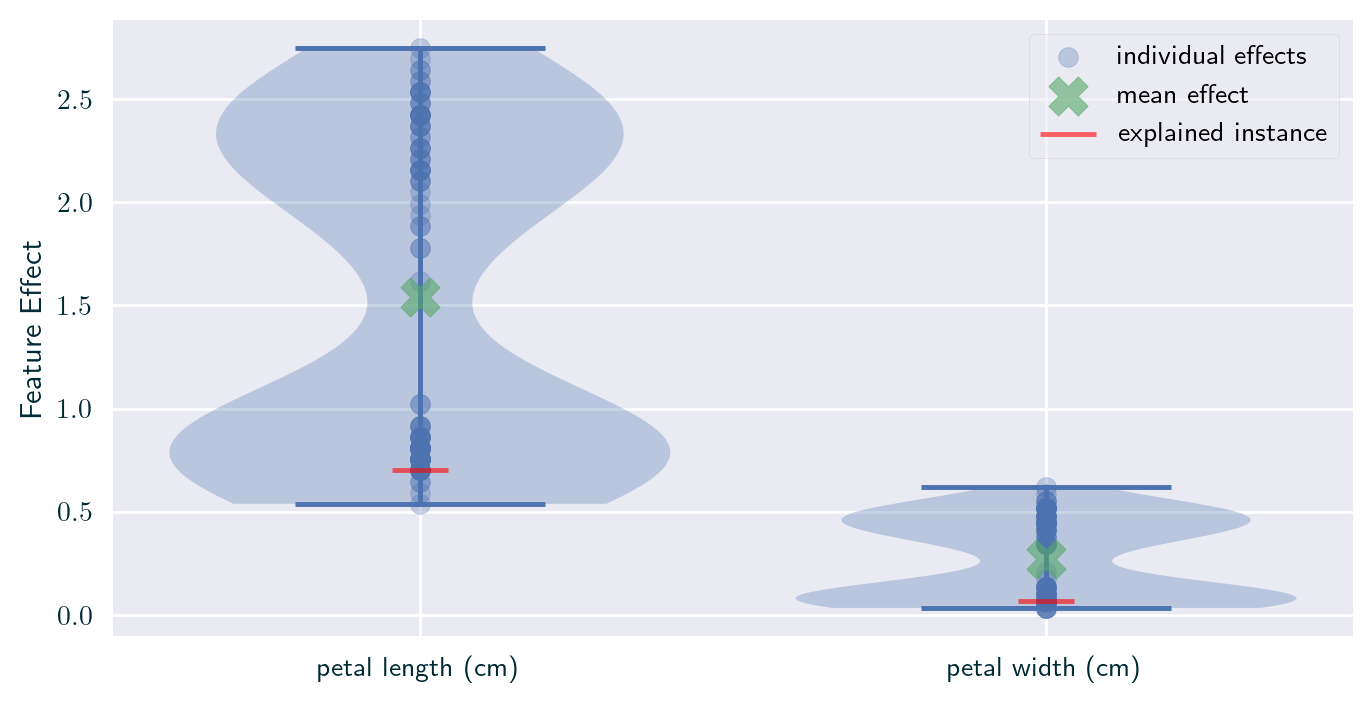
Individual Effect

Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Incomparability of Parameters
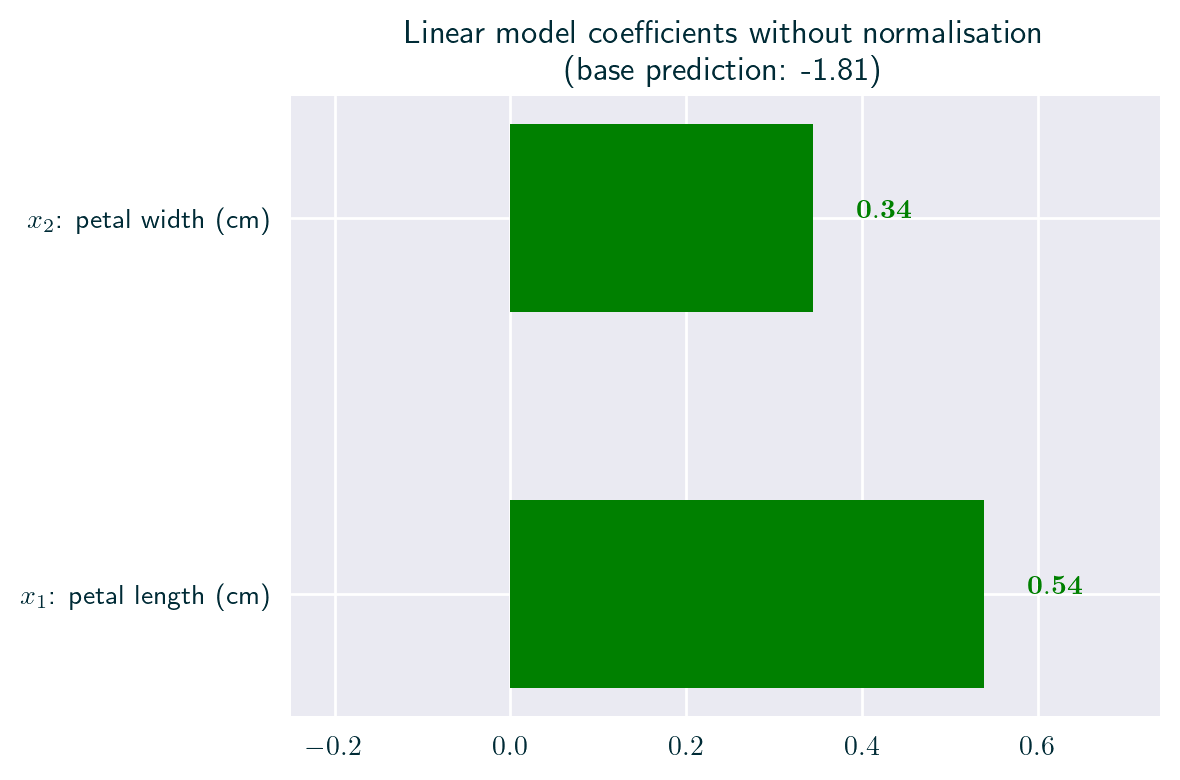
Incomparability of Parameters
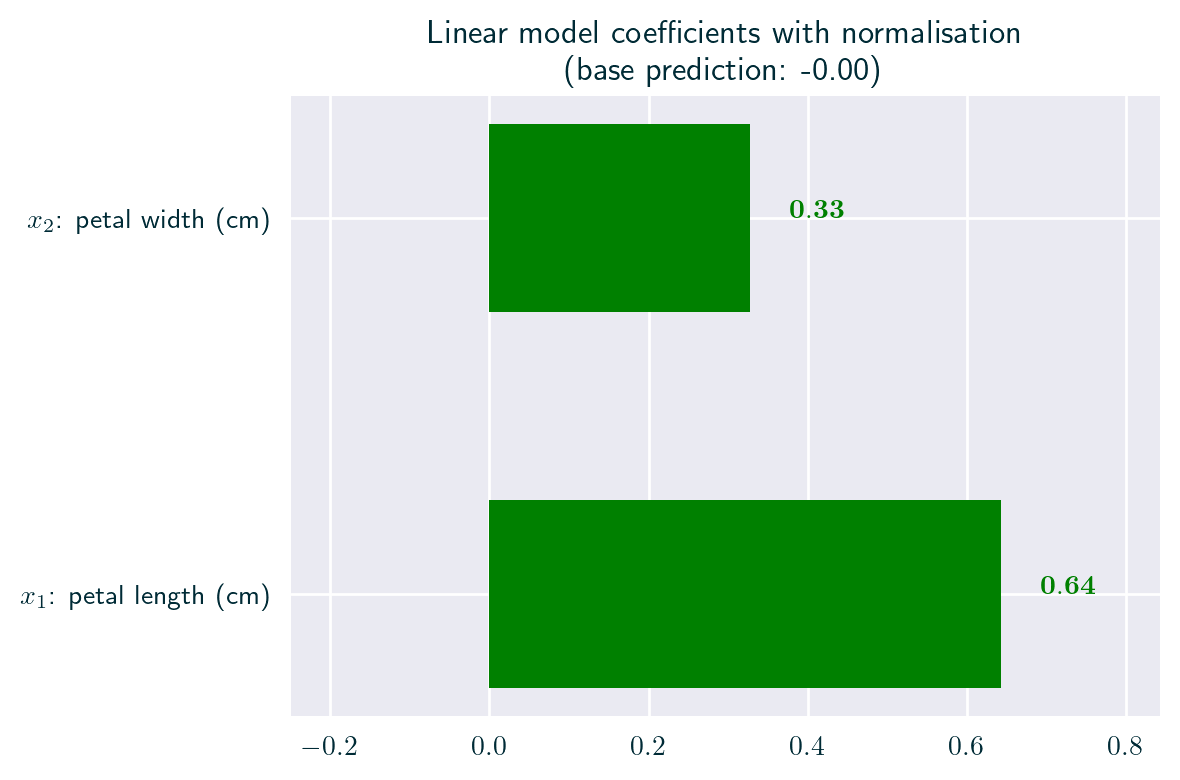
Incomparability of Parameters
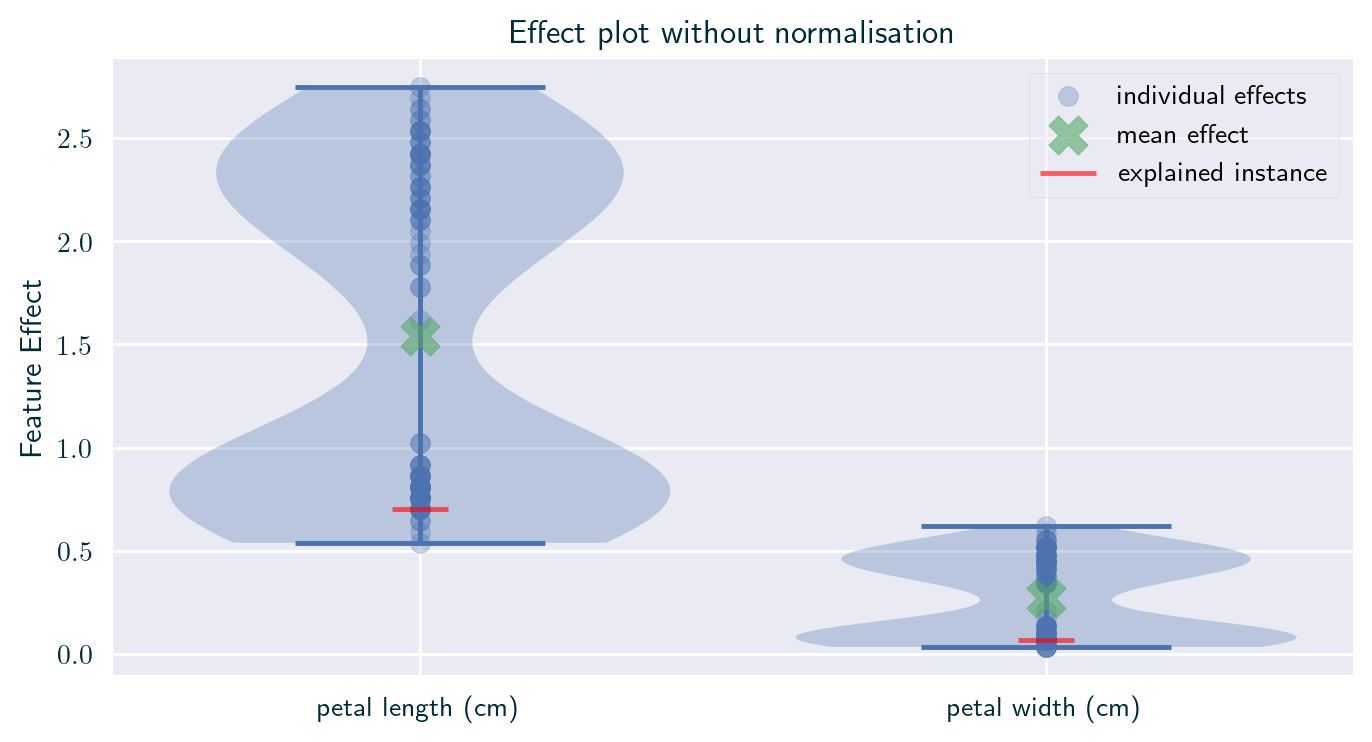
Incomparability of Parameters
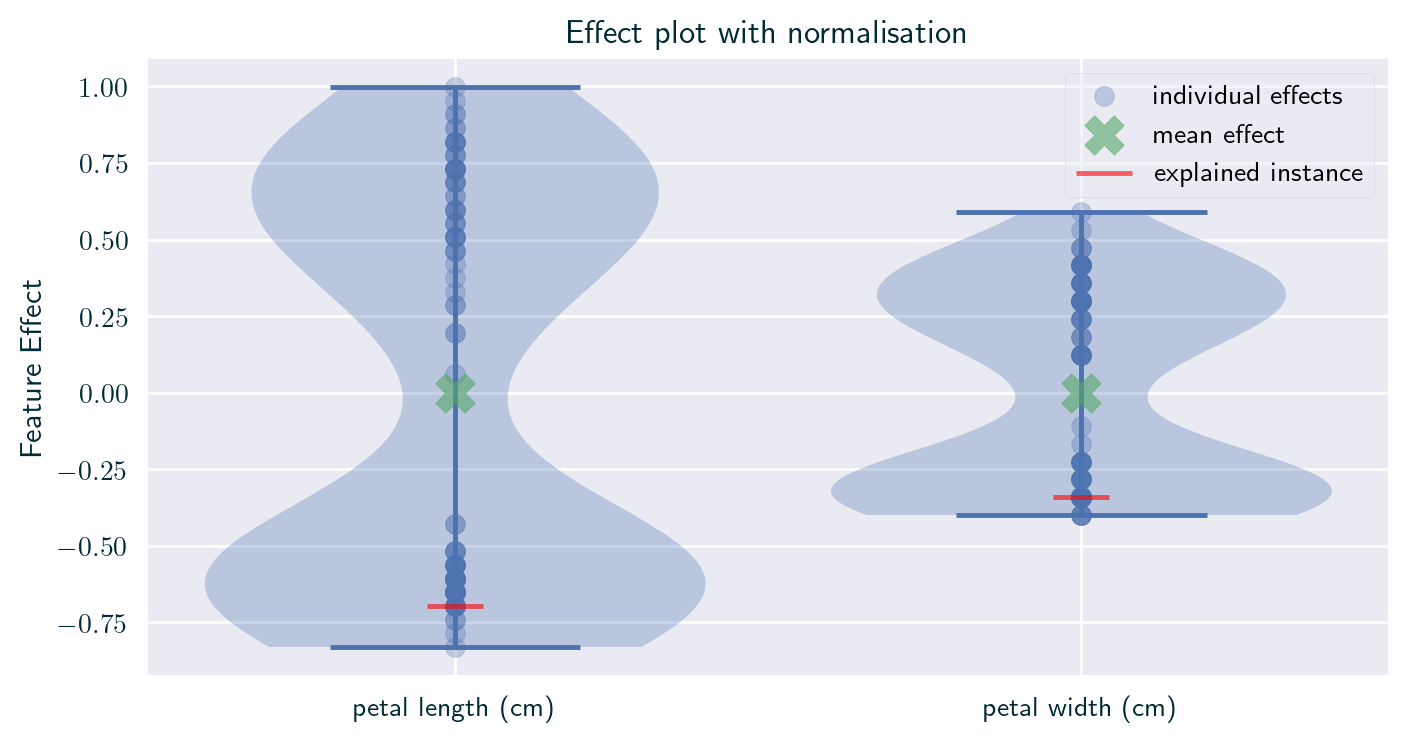
Incomparability of Parameters